
鉄道業界におけるビックデータの活用方法
この記事では、鉄道・通信業等が協力して実証実験を行っている、鉄道業界におけるビッグデータの活用法について、他業種のビッグデータ活用例と比較しつつ解説しています。
西武鉄道とヤフーは2019年8月1日、西武鉄道が運行する路線の混雑を予測し、Webサイトで発信する実証実験を実施すると発表しました。この実証実験は、8月19日から9月20日にかけて実施されます。
また、東京メトロ・NTTのタッグは、2019年7月29日に「東京の魅力・活力の共創」・「インフラの安全・安定性の向上」・「移動の円滑性向上」に関する協業に合意、両社が保有するデータ・技術を相互活用すると発表しています。
幅広い属性の乗客が利用する鉄道ビッグデータは、様々なジャンルで利活用が期待されながら、決定的な利用法が確立されていない状況にあります。そのような中、ビッグデータと人工知能(AI)を活用し、混雑の緩和や快適性の向上を目指す動きが活発化しています。
情報量が膨大であるがゆえに使いこなせなかったビッグデータは、次第にその全容を紐解かれています。今回は、ビッグデータの活用を試みた具体例を、いくつか紹介します。
目次
鉄道各社が実現したいことは何なのか
鉄道会社が集めているビッグデータは、果たして何のために必要なのでしょうか。消費者の立場としては、どちらかというと「商業施設に移動する客層の分析」といったように、グループ企業の売上に直結する情報の集計を想像しがちですが、あくまでも鉄道会社側としては「利便性」を高めるための利活用を検討しています。
冒頭でお伝えした、西武鉄道・ヤフーによるビッグデータ実証実験は、ヤフーが提供している「Yahoo!乗換案内」などに蓄積される『将来の予定を含む路線検索履歴』のビッグデータを利活用する形で行われます。データは個人が特定できないように統計化された後、AIによる解析を行い、各駅の混雑パターンの推定に用いられます。出口調査として、西武鉄道の駅別・時間帯別の降車人数データを掛け合わせ、混雑予測の精度を向上させる仕組みとなっています。
通勤・イベント・野球など、何かにつけて混雑する時間が分かれば、スピーディかつストレスなく行動するにはどの電車に乗ればよいのか、ある程度当たりをつけやすくなります。なお、実証実験が行われる駅は、池袋駅・西武新宿駅・高田馬場駅・国分寺駅・西武球場前駅の5駅です。
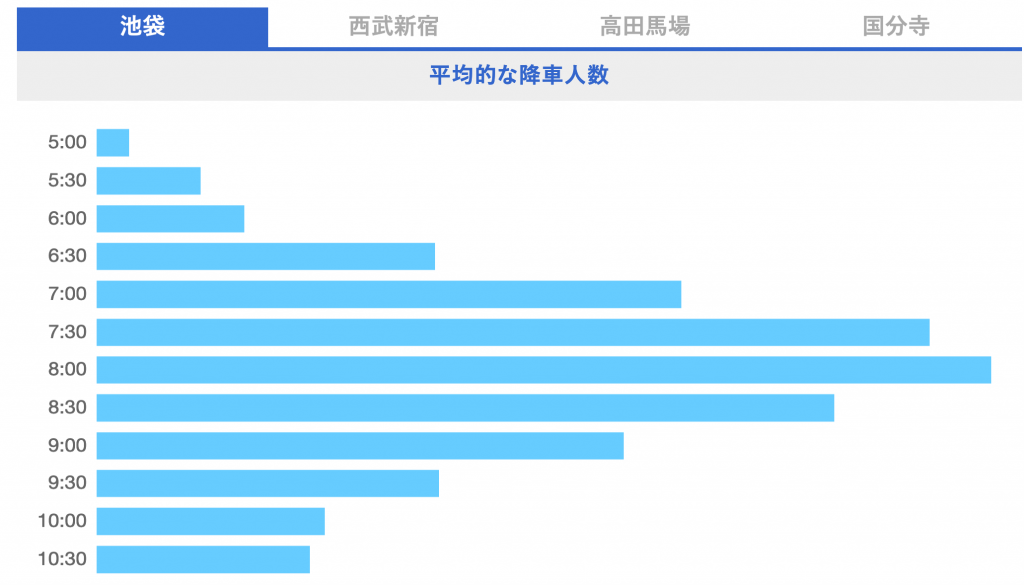 出典元:https://www.seibuapp.jp/railways/congestion/terminal.html
出典元:https://www.seibuapp.jp/railways/congestion/terminal.html
小売業のビックデータ活用と比較した際の「方向性の違い」
すでにビッグデータをマーケティングに活用している小売業では、データを「生もの」のようにとらえることが一般化しつつあります。顧客の実態把握のために必要なデータを考え、集めて解析するために、ビッグデータとAIがあるというスタンスです。
ローソンでは、Pontaからの購買データを解析することで、一部商品の売上のうち「6割はたった1割のヘビーユーザーによるもの」だとはじき出した例があります。
また、好きな商品ばかり購入するのか、新しい商品が好きなのか、対面レジが好きなのか、自動決済が好きなのかなど、顧客の好み・スタンスをも把握できる精度となり、店舗作り・仕入の最適化といった方向性からビッグデータを利活用しています。
これに対し鉄道業界では、長きにわたり交通インフラとしての安全性・効率性が求められてきました。その結果、JR各社に代表されるような、かつて世界中の人々を驚かせた「秒単位で作成されるダイヤグラムを遂行する能力」や、福知山線脱線事故を引き起こす遠因となった「わずか数分の遅れで人格を否定される日勤教育」など、人間に課すには酷に感じられるまでの正確性を求められる社風が培われました。
これらの技術は、運転手の技量や整備に関わるスタッフの技能という部分に多くを依存するもので、その個々人の能力の高さは尊敬に値するものです。しかし、鉄道路線の老朽化・保安員の高齢化など、人手不足が進む中で人員の確保も厳しくなり、データを利活用して作業の効率化を図る動きがJRなどの鉄道各社で進むようになりました。
小売業が売上増のためにデータを利活用するのに対し、鉄道会社は安全性と効率性の両立を図ることが目的となっています。小売業のような数値目標を立てにくく、データを利活用できる範囲を絞り切れない一面があったことから、活用法を得るために新たな策を講じることとなりました。
誰もがスムーズ・安全に使える鉄道をめざして
JR東日本・経済産業省は、鉄道関連のビッグデータについて、その活用法を一般募集するコンテストを行いました。鉄道会社が生データを取引先以外に外部提供することは異例のことで、社外から幅広くアイデアを採用し、人手不足への対応を図りたい考えです。
コンテストで使われたデータは、自然による原因不明の影響などを受けた「線路の歪み量」データであり、データ分析によって「数か月先」の線路の歪み量を予測し、正確さを競うのが目的です。鉄道に関わる優秀な人材の能力を補てんするためには、社外のICT技術をどれだけ鉄道の維持に結び付けられるかが、今後の課題になるものと推察されます。
※第4回ビッグデータ分析コンテスト実施サイト(https://signate.jp/competitions/136)
まとめ
一口にビッグデータと言っても、集まるデータの量も質も業種によって違います。
鉄道業界では、人材不足の中で今までと同じ安全性・効率性を確保すべく、ビッグデータの活用法を模索しています。
保安員の技術に依存していた「設備の故障予知・寿命予測」に加えて、将来的には、通勤・生活・観光といった観点から「交通手段の選択肢を増やす」方向への利活用も期待されます。成熟が進むことで、私たちが持つ「混雑」という概念が、徐々に変容していくかもしれません。
合わせて読みたい!
販売データ活用を迅速化!輸送実績可視化ツールとは?
運行データ等を活用したデータ活用の効率化およびそれによる高速バスの収益を最大化させるため、他システムからのデータの取り込みやデータの統合、BIツールへの可視化を自動化できる基盤の構築した取り組みについて紹介します。
▼もっと詳しく
メールマガジンに登録しませんか?
本サイトを運営しております株式会社Will Smartは公共交通・物流・不動産などの社会インフラの領域においてIoT技術やモビリティテックを活用したGX×DXの取り組みに注力しております。
メールマガジンではWill Smartの最新の取り組み事例やミライコラボのコンテンツ情報をなどお届けします。下記の登録フォームよりぜひご登録ください。















